Echo: Towards General AI Prediction
2026-03-27
Contributors: Zhengwei Tao1,2,*, Rui Min1,*, Hongfeng He1,*, Jialong Wu1,2, Baixuan Li1, Liang Chen1, Wentao Zhang2, Kuan Li1
Affiliations: 1UniPat AI 2Peking University
*Equal Contribution
Correspondence: zhengweitao@unipat.ai, kuanli@unipat.ai
General AI Prediction Leaderboard
March 2026 · Elo Score









Introduction
Prediction has never been absent from human history, the question “Why do we predict?” has rarely required an answer. From prehistoric hunters anticipating trajectories and prey behavior, to farmers reading the sky, to traders interpreting markets—today we forecast game outcomes, stock prices, and even presidential elections. At scale, in modern prediction markets, forecasting becomes a recursive echo of millions of minds predicting one another. In doing so, it encodes social meaning, economic value, and spans the full spectrum of human computation from the finite to the boundless.
We present Echo, a full-stack prediction intelligence system built around EchoZ-1.0, the first large language model to be trained end-to-end with the Train-on-Future paradigm. Echo consists of three core components: (i) General AI Prediction Leaderboard, a dynamic evaluation engine that addresses key limitations in existing prediction benchmarks, including limited categories and poorly aligned prediction points across models; (ii) Train-on-Future, a post-training pipeline that teaches models to reason about future events rather than rely on past answers; and (iii) an AI-native prediction API that produces structured, evidence-based probability reports across a wide range of domains.
General AI Prediction Leaderboard
A prediction problem is a question whose correct resolution lies in the future. Formally, each prediction instance $\mathcal{Q}_i$ is associated with a candidate answer set $\mathcal{A}_i$ and a resolvement horizon $D_i$ (in days), where the true outcome remains unknown until some future time. The goal of a forecasting model is to assign, before resolvement, a probability distribution over the possible answers.
Given such a prediction question $\mathcal{Q}_i$, the model produces at prediction time $t < D_i$ a probability vector:
This distribution represents the model’s belief over all candidate outcomes at time $t$, under the information available before the question resolves. A reliable benchmark should therefore evaluate the quality of $\hat{\mathbf{p}}_i(t)$ across a diverse set of prediction questions, while also providing a principled basis for comparing forecasts made at heterogeneous prediction times. Existing online benchmarks fall short on both requirements, due to two structural deficiencies:
Leaderboard Design
To tackle the existing benchmarks' deficiencies, the Leaderboard is built around a three-stage pipeline for fair and scalable prediction evaluation. First, it acquires questions from three complementary sources for broad coverage. Second, it schedules and prioritizes prediction samples over each question’s lifecycle. Finally, evaluation is framed as pairwise battles and a global Elo-style optimization produces the final leaderboard, emphasizing robustness, reliability, expeditiousness, diversity, and flexibility.
Three-Source Data Acquistion and Automated Resolvement
Prediction Data Selection: Two-Phase Algorithm
In principle, each prediction problem can be forecast at arbitrary time points before resolution, making exhaustive benchmarking impossible. We therefore introduce an efficient two-phase data selection scheduler designed to achieve three goals: (1) cover each question’s lifecycle with well-distributed prediction timestamps; (2) stabilize the day-to-day prediction workload; and (3) ensure a steady flow of resolved questions and maintain a live, continuously updated benchmark.
Phase 1 — Total Prediction Count Estimation
Unlike static benchmark questions, prediction questions evolve over time: the same question answered at different timestamps can carry different information and have different evaluation value. More concretely, later predictions are usually informed by more evidence and therefore tend to be more stable as resolution approaches. In our benchmark design, longer-horizon questions are assigned more prediction points, since they leave more time for new evidence to emerge. But if we increase the number of prediction points linearly with question lifetime, the cost grows too quickly. For example, a 30-day question would require 10 times as many predictions as a 3-day question. To avoid this, we use a logarithmic schedule to increase prediction points as ($D_i$) grows. Let $T_i$ denote the target number of prediction points for question $i$. We implement this schedule with the following form:
We fit the parameters so that the schedule yields approximately 4 and 7 predictions for question lifetimes of 10 and 90 days, respectively. This logarithmic compression also reduces the spread in prediction frequency across questions, which helps naturally smooth the distribution of final-prediction dates.
Phase 2 — Priority Scoring
To decide which questions should be predicted next while keeping the schedule balanced over time, we assign each question a priority score. Let $W_i$ denote days elapsed since the last prediction, $P_i$ the number of predictions already completed, $R_i = T_i - P_i$ the remaining count, and $D_i'$ the remaining time until resolvement. The priority score is:
A higher $S_i$ means the question should be given higher priority. This scoring rule has two desirable properties. The first is elastic recovery: if a question remains unsampled for a long period, $W_i$ continues to grow until the question is scheduled again. This helps preserve coverage across the question's lifecycle (goal 1). The second is resolution-aware prioritization: as $D_i'$ gets smaller, the target interval $D_i' / R_i$ also gets smaller. This gives questions approaching resolution higher priority and helps maintain a steady flow of resolved questions (goal 3). Finally, each day the scheduler selects the top-$B$ questions by $S_i$. The budget $B$ controls the daily prediction volume (goal 2).
Multi-Point Aligned Elo Framework
The framework's core mechanism is prediction-point alignment. We compare models only when they make predictions on the same question at the same prediction point, ensuring the same information and time remaining until resolution. We then jointly estimate model ratings with a Bradley-Terry model by maximum likelihood.
Battle Construction
After alignment, we compute a Brier Score $\text{BS} = (1 - p^{c})^2$ for each prediction, where $p^{c}$ is the probability assigned to the correct outcome. Lower scores indicate better prediction performance. Each aligned comparison is then treated as a battle, indexed by $k$, with competitors denoted by $a_k$ and $b_k$.
Soft label $v_k$: A binary win/loss label is too coarse for probabilistic forecasting because it cannot capture differences in confidence. Even when two models predict the same correct outcome, they may assign very different probabilities. A strict binary label would treat these forecasts as equivalent, which would ignore meaningful differences in calibration. To preserve this information, we map the Brier Score difference between models $a_k$ and $b_k$ to a continuous target $v_k \in (0,1)$, where larger values mean that model $a_k$ performs better than model $b_k$ by a wider margin:
When the two models have the same Brier Score, $v_k = 0.5$. If model $a_k$ achieves a lower Brier Score than model $b_k$, then $v_k$ moves closer to 1; if $a_k$ performs worse, then $v_k$ moves closer to 0. The parameter $\sigma$ controls the sensitivity of the soft outcome to a given Brier Score gap.
Weight $w_k$: Longer-horizon forecasts are generally harder because they are made with less prior information. We therefore weight each battle by its prediction lead time $\Delta t_k$:
The parameter $\gamma$ controls the weighting strength. Each battle is therefore written as $(a_k, b_k, v_k, w_k)$, where $a_k$ and $b_k$ are the two models being compared, $v_k$ is the soft outcome, and $w_k$ is the battle weight.
Bradley-Terry MLE
Let $\mathbf{r}$ be the vector of model ratings, and let $r_i$ denote the rating of model $i$. The Bradley-Terry model maps rating differences to pairwise win probabilities. In battle $k$, the probability that model $a_k$ beats model $b_k$ is:
We estimate the ratings by maximizing the following weighted log-likelihood, where $v_k$ is the observed soft outcome and $w_k$ is the battle weight:
This objective assigns higher ratings to models whose implied win probabilities match the observed soft outcomes across battles, with greater emphasis on battles that carry larger weights.
$\hat{\mathbf{r}} = \arg\max_{\mathbf{r}} \mathcal{L}(\mathbf{r})$ is solved with L-BFGS-B. Because the Bradley-Terry negative log-likelihood is convex in $\mathbf{r}$, the optimization converges to the global optimum.
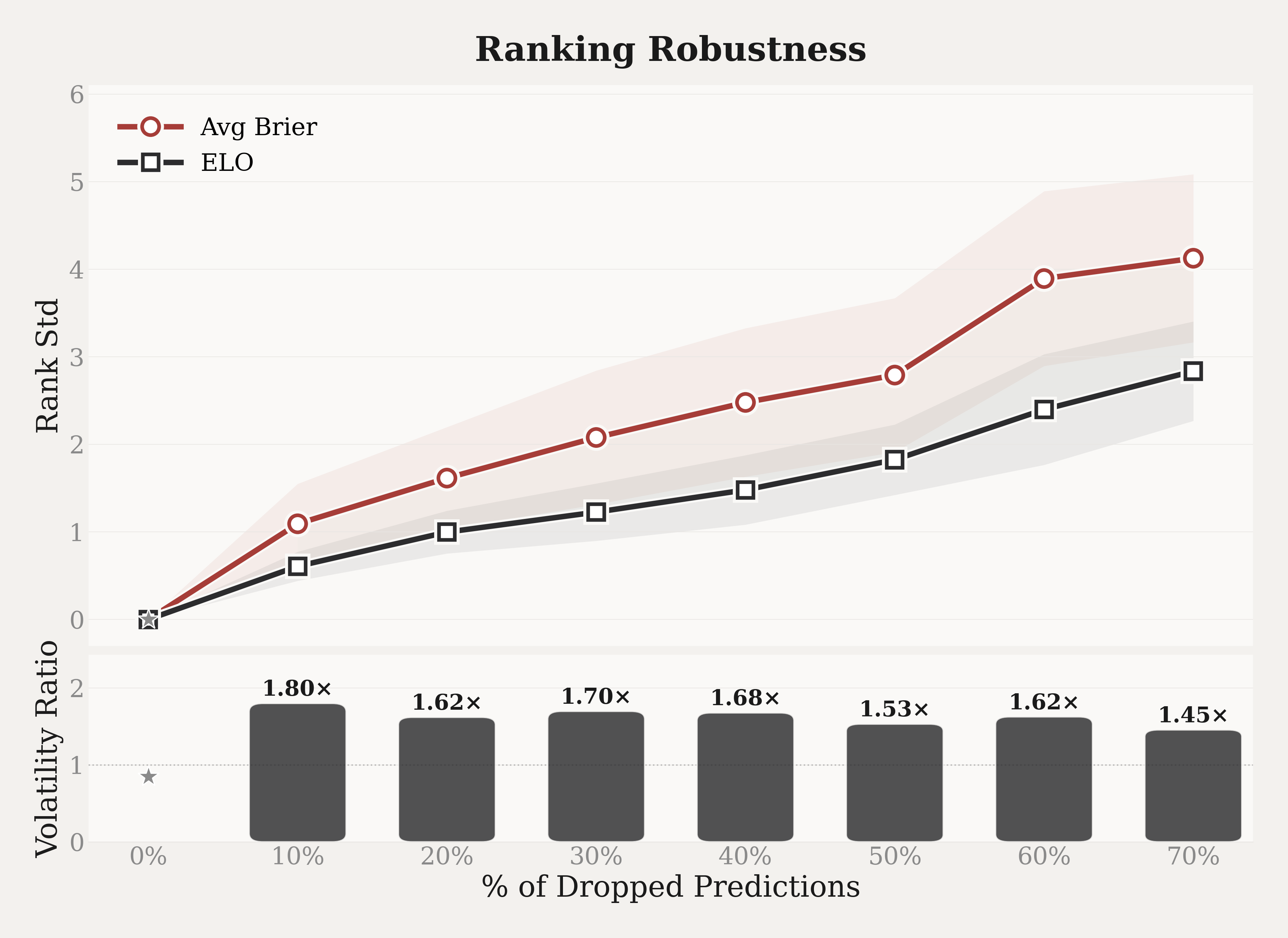
Robustness: Rank Stability Under Missing Scheduled Predictions
In practice, different models may not always complete their scheduled predictions on time every day due to API failures or server interruptions. A practical ranking method should therefore remain stable when some scheduled prediction days are missed. Average Brier Score is sensitive to this because it is computed only over the questions a model has answered. Once some days are omitted, the score is based on a smaller subset of questions, which may not have the same difficulty as the full set. As a result, the ranking can become unstable and may fail to genuinely reflect a model's prediction performance. Elo works differently. Each battle compares two models only on questions that both of them answered. If one model misses a scheduled prediction day, the battles for that day simply do not happen, which means the remaining battles are still based on shared questions. As a result, missing scheduled predictions reduce the number of comparisons, but they do not change which questions each battle is based on.
In our experiment, we select a subset of models and simulate missing scheduled predictions by randomly dropping between 10% and 70% of their prediction days. For each drop rate, we run 50 trials and record the standard deviation of each model's rank across trials using the recomputed rankings. This measures how much the ranking varies when different scheduled prediction days are missing. We also report the gap using the Volatility Ratio (Average Brier rank Std ÷ Elo rank Std).
Reliability: Rank Consistency Under Model Set Variation
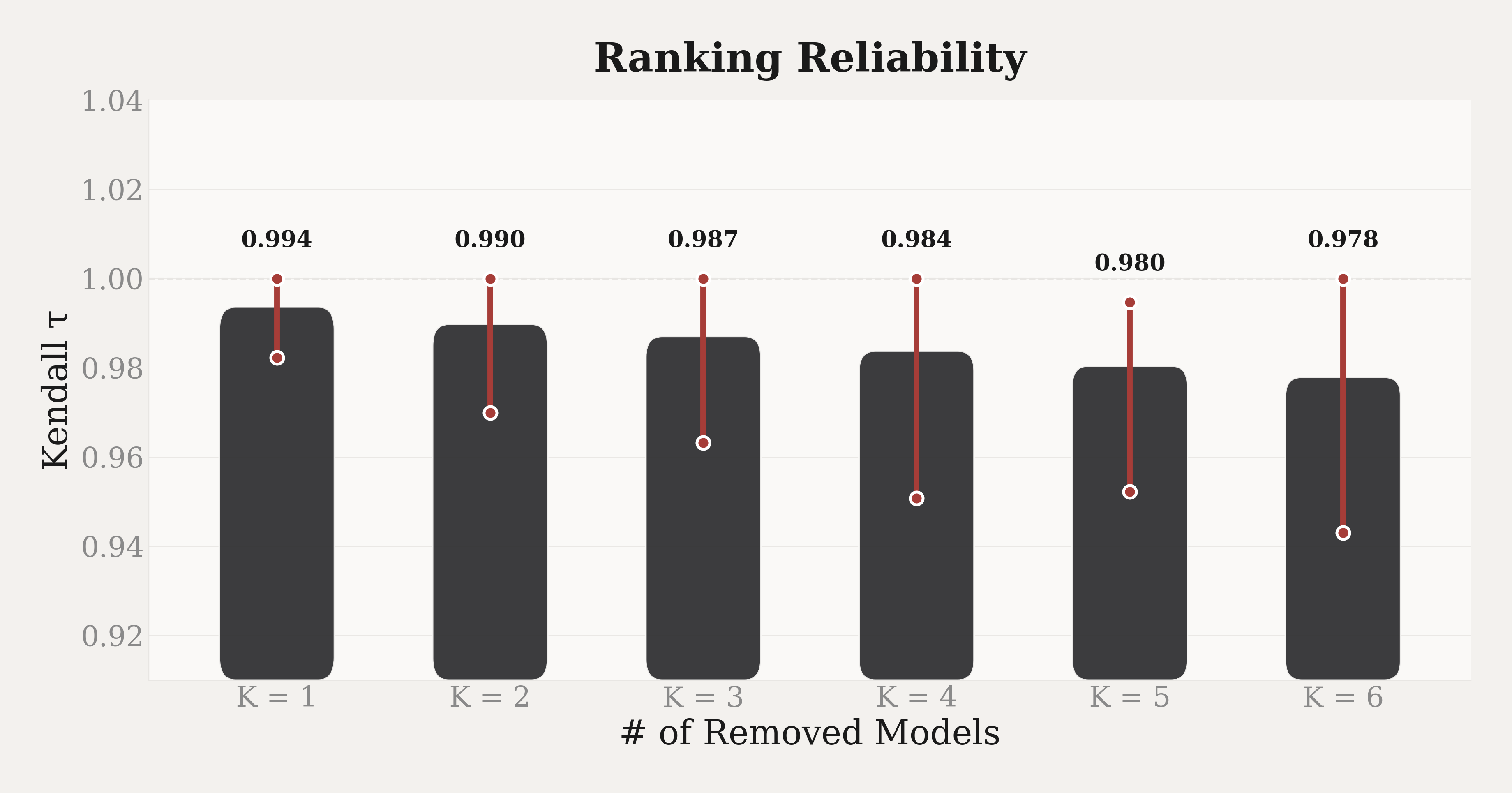
Since Average Brier Score computes each model's score independently, adding or removing other models does not affect the ranking of the remaining models. The situation is different for Elo rankings, which estimate all model ratings jointly from the full set of pairwise battles. When a model is removed, the ratings of other models may shift because some battles are no longer observed. If these shifts are large, the Elo ranking becomes unstable as the model set changes. To evaluate how sensitive Elo is to such changes, we design a Leave-$K$-Out experiment.
We first fit the Bradley–Terry model using all battles from the full model set and treat the resulting ranking as the reference. We then vary $K$ from 1 to 6. For each $K$, we sample a large number of model combinations to remove. Specifically, we remove all battles involving those $K$ models and refit the Bradley-Terry model on the remaining ones. We then compare the new ranking with the reference ranking after excluding the removed models. We use Kendall's $\tau$ to measure how much the ranking changes:
Here $N$ is the number of established models in the full model set, and the denominator $\binom{N-K}{2}$ indicates the total number of model pairs among the remaining models. For each pair, we check whether the two models appear in the same relative order in both the reference ranking and the new ranking. If they do, the pair is concordant ($n_c$); if the order is reversed, the pair is discordant ($n_d$). A value of $\tau = 1$ means all pairwise orders are preserved, while $\tau = 0$ means the number of preserved pairs equals the number of flipped pairs. For each $K$, we report the mean $\tau$ and the 95% confidence interval across all sampled removal combinations.
Expeditiousness: New Model Ranking Convergence
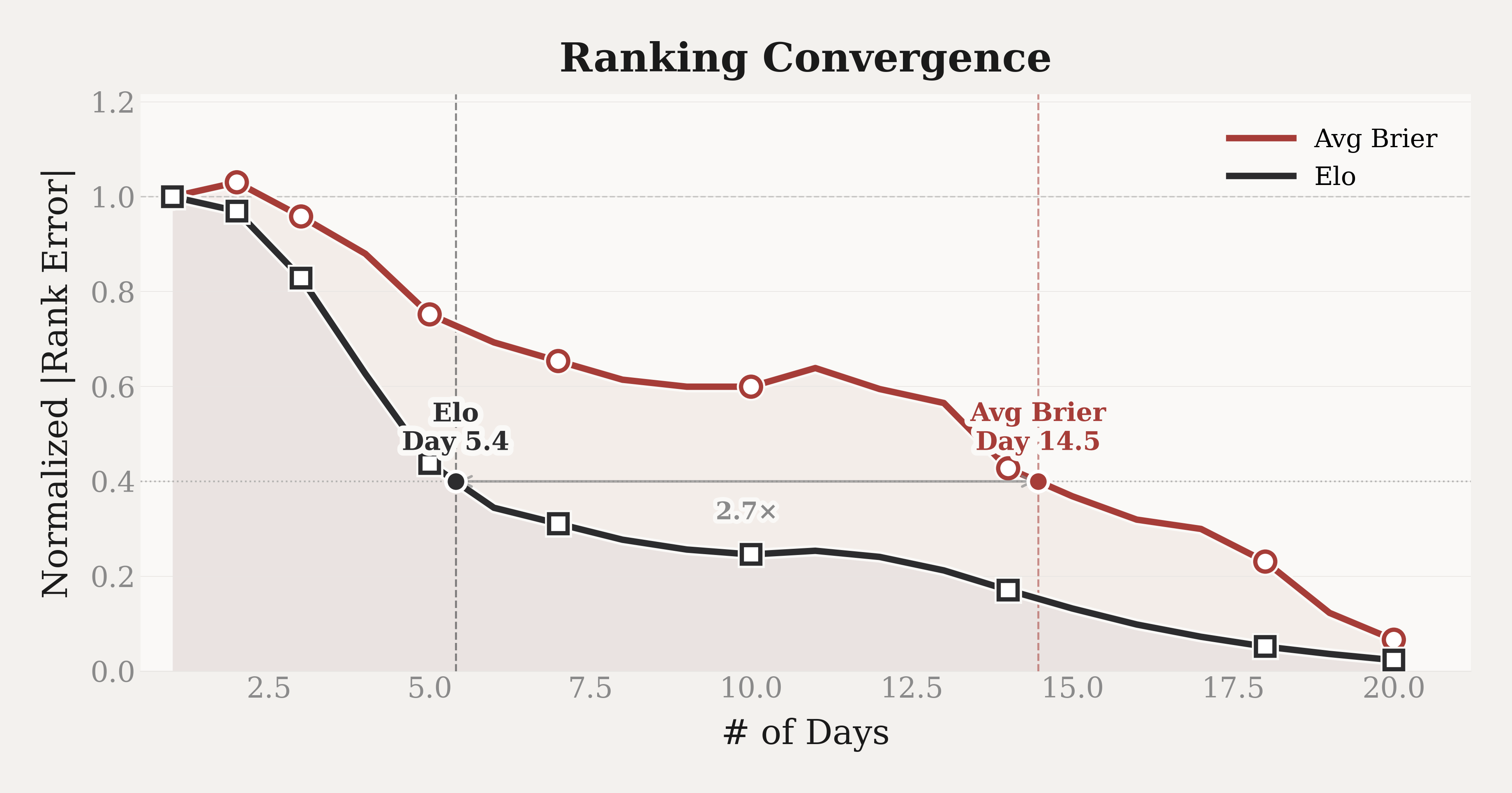
When a new model joins the leaderboard, only a subset of questions has resolved, and those questions are more likely to be earlier-resolving ones. Under Average Brier Score, the new model is ranked only on this subset, while established models are evaluated on a broader mix of questions with both short and long resolution horizons. The two groups are therefore evaluated on different question distributions, which makes the comparison unfair. As more questions resolve over time, the distribution changes, and the Average Brier ranking changes with it.
In terms of the Elo ranking, each battle compares two models on the same question at the same prediction time. The comparison is therefore made within a shared setting. The difficulty of the question is shared by both models in that battle and does not favor one side over the other. Although a new model with only a few battles may receive a noisier rating, each battle still provides a valid relative comparison, and the rating is not systematically biased by the resolved question set. This suggests that Elo rankings would approach their stable values faster than Average Brier rankings when a new model joins. We test this with the following experiment. We simulate cold-start entry for each established model over a 20-day observation window. On each day $d$, we define the Rank Percentile Error as follows:
where $N$ is the number of established models. For a given model $m$, we pretend that it has just joined and compute its rank using only its first $d$ days of predictions; this is denoted $\text{rank}_m(d)$. All other established models still use their full prediction history. We then compare this early rank with $\text{rank}_m^\ast$, the rank of model $m$ computed from all 20 days of its predictions. The absolute difference between $\text{rank}_m(d)$ and $\text{rank}_m^\ast$, divided by $N$, is the Rank Percentile Error on day $d$. We repeat this for every established model and average the resulting errors. For visual comparison, the figure normalises each method's error curve by its Day-1 value, so the two methods can be compared on the same scale.
Diversity: Coverage Across Domains and Horizons
Prediction performance varies across domains. A model may perform well on political events but struggle with financial or scientific questions. To reduce domain bias in the rankings, Echo's question pool spans 7 domains: Politics & Governance, Economy & Finance, Sports & Entertainment, Science & Environment, Crypto & Digital Assets, Esports & Gaming, and Other. New questions are added daily so the benchmark continues to cover ongoing real-world events. The domain distribution is as follows:
Question Distribution by Domain
7 categories
Active prediction question distribution as of March 27, 2026
Flexibility: Open Participation Interface
Existing dynamic prediction leaderboards require participants to submit their predictions periodically to ensure the effectiveness of the evaluation, which placed a significant burden on them. Thanks to the aforementioned design mechanism, Echo allows participants to freely choose the submission date and topic. The experimental results above verify that Echo can still provide reliable evaluation results under any submission conditions.
EchoZ-1.0: Train on the Future
Deep Research Agent Framework for Prediction
EchoZ-1.0 is built on the ReAct framework. At each timestep $t$, the agent performs three steps: it first generates a thought $\theta_t$ (what to do next and why), then takes an action $\alpha_t$ (such as running a web search or visiting a page), and finally receives an observation $o_t$ (the result of the action). These three steps form a triple $(\theta_t, \alpha_t, o_t)$. As the agent iterates, the full history of all previous triples accumulates into a trajectory:
At each step, the agent decides what to do next based on the question $\mathcal{Q}_i$ and everything it has seen so far ($H_t$):
The loop continues until the agent decides to produce a final answer. At that step $T$, the action $\alpha_T$ is set to "answer" and the agent outputs a probability distribution over the possible outcomes:
This framework allows the model to actively search for information and reason over multiple steps before making a prediction. However, training such an agent introduces two key difficulties.
Deficiencies of Train-on-Past
Three Core Mechanisms of the Train-on-Future Pipeline
Automated Rubric Search
Each model produces a prediction trajectory for every question, recording its full prediction process from information gathering to final probability output. We cannot rely solely on resolved outcomes to judge trajectory quality, for two reasons. First, prediction outcomes are noisy: a model can reason well and still be wrong, or reason poorly and happen to be right. Second, many questions take days or weeks to resolve, making outcome-based feedback slow and sparse. We therefore need a way to evaluate the prediction process itself. The goal of the rubric search is to find a rubric that can assess trajectory quality and produce model rankings consistent with the Elo ranking.
Directly using an LLM to score an entire trajectory produces coarse-grained supervision and would lack consistency across runs. Instead, we decompose the evaluation into concrete dimensions, such as source reliability and probability calibration. Each dimension has clearly defined scoring levels, and together they form a rubric. The LLM judge scores each trajectory dimension by dimension. Compared to a single holistic score, this structured approach produces more stable and fine-grained results.
However, designing a good rubric by hand is difficult. Prediction questions are inherently noisy: even a well-reasoned trajectory can lead to a wrong outcome, and a poorly reasoned one can happen to be correct. Without grounding in data, a hand-designed rubric may not capture the dimensions that actually correlate with forecasting accuracy. This introduces bias into the evaluation. On top of that, different domain categories have different characteristics. The reasoning patterns that lead to accurate predictions in Sports & Entertainment could be different from those in Crypto & Digital Assets, and a single rubric cannot capture both well.
To avoid these issues, we ground the rubric design in data rather than human intuition. We frame it as a data-driven search problem: the search objective is to maximise Spearman's $\rho$ between the rubric-based model ranking and the Elo ranking. We run the search independently for each of the primary domain categories, starting from a general rubric. In each round, an LLM generates new rubric candidates informed by feedback from previous rounds, such as which dimensions contribute to the scoring process. Each candidate is evaluated on held-out data, and the top-performing candidates are retained for further iterations.
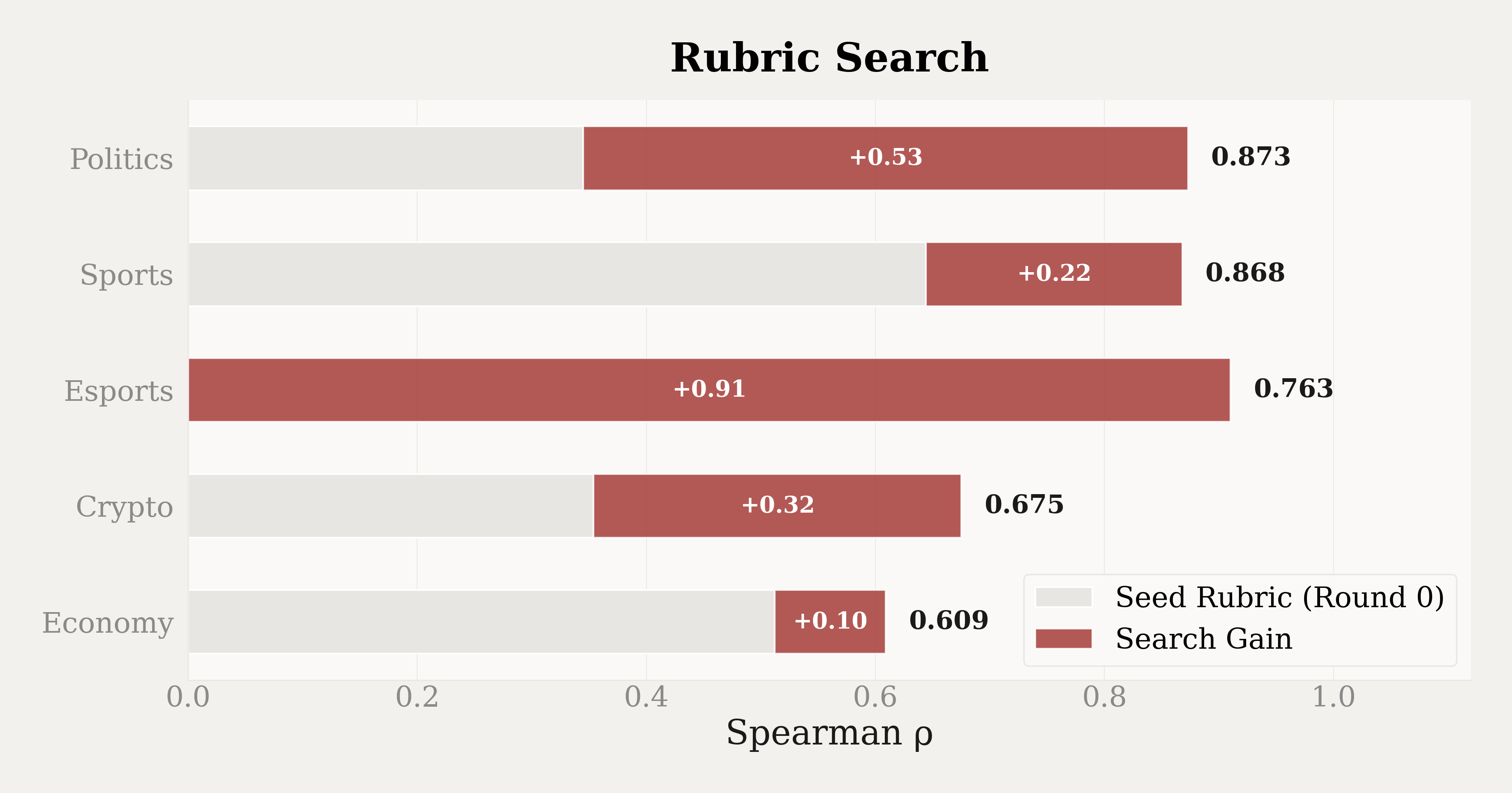
We show part of the rubrics as follows:
Rubrics by Domain
▶Resolution Criteria Parsing5 · 3 · 1
Evaluates whether the trajectory explicitly extracts and strictly tests evidence against all specific technical constraints and edge cases in the prompt.
▶Rhetoric vs Execution Disambiguation5 · 3 · 1
Assesses the ability to separate a politician's public threats, promises, or social media posts from formal administrative, legal, or military execution.
▶Primary Institutional Sourcing5 · 3 · 1
Measures the effort to bypass secondary news summaries and directly access authoritative government, legal, or military repositories.
▶Procedural Constraint Assessment5 · 3 · 1
Evaluates understanding of specific rules, schedules, and hurdles of relevant government, legal, or military institutions.
▶Timeline Feasibility Calculation5 · 3 · 1
Measures whether the trajectory calculates the exact time left and assesses if the required actions are logistically and procedurally possible.
▶Geospatial and Entity Precision5 · 3 · 1
Assesses the rigor of verifying exact geographic locations, borders, or official territorial and sovereign definitions.
▶Negative Evidence Weighting5 · 3 · 1
Measures whether the trajectory actively uses the absence of information or action as a strong predictive signal.
▶Chronological Boundary Enforcement5 · 3 · 1
Checks strict adherence to the exact start and end dates specified in the prompt, ensuring past events fall inside the valid window.
▶False Positive Filtration5 · 3 · 1
Assesses the ability to identify and discard misleading search snippets, misdated articles, or misattributed actions.
▶Quantitative Base Rate Calculation5 · 3 · 1
Checks if the trajectory establishes a quantitative historical baseline or frequency to mathematically anchor its projection.
▶Diplomatic and Proxy Disambiguation5 · 3 · 1
Assesses the ability to differentiate between the various roles nations play, such as mediators versus physical hosts, or proxies versus states.
▶Prediction Market Rule Calibration5 · 3 · 1
Evaluates the extraction of specific odds from prediction markets and the analysis of their underlying resolution rules.
▶Catalyst and Off-Ramp Tracking5 · 3 · 1
Evaluates the identification of specific upcoming events that could trigger or prevent the predicted outcome.
▶Contradiction Resolution5 · 3 · 1
Assesses how the trajectory handles conflicting reports or data points discovered during the investigation.
▶Reporting Lag Awareness5 · 3 · 1
Evaluates whether the trajectory accounts for delays in official reporting or docket updates.
▶Recent Window Monitoring5 · 3 · 1
Checks if the trajectory specifically searches for updates in the immediate 24-48 hours prior to the simulated current date.
▶Semantic and Legal Rigor5 · 3 · 1
Evaluates how strictly the trajectory distinguishes between closely related but legally or militarily distinct terms.
▶Tool Failure Adaptation5 · 3 · 1
Evaluates the trajectory's persistence and adaptability when technical tools fail to return expected data.
▶Sustained Condition Analysis5 · 3 · 1
Evaluates whether the trajectory verifies if a specific condition was sustained over a required period rather than a momentary blip.
▶Evidence-Probability Calibration5 · 3 · 1
Measures how strictly the final probability reflects the gathered evidence, base rate math, and resolved contradictions.
Performance Analysis
Ranking Robustness Across Sensitivity Parameters
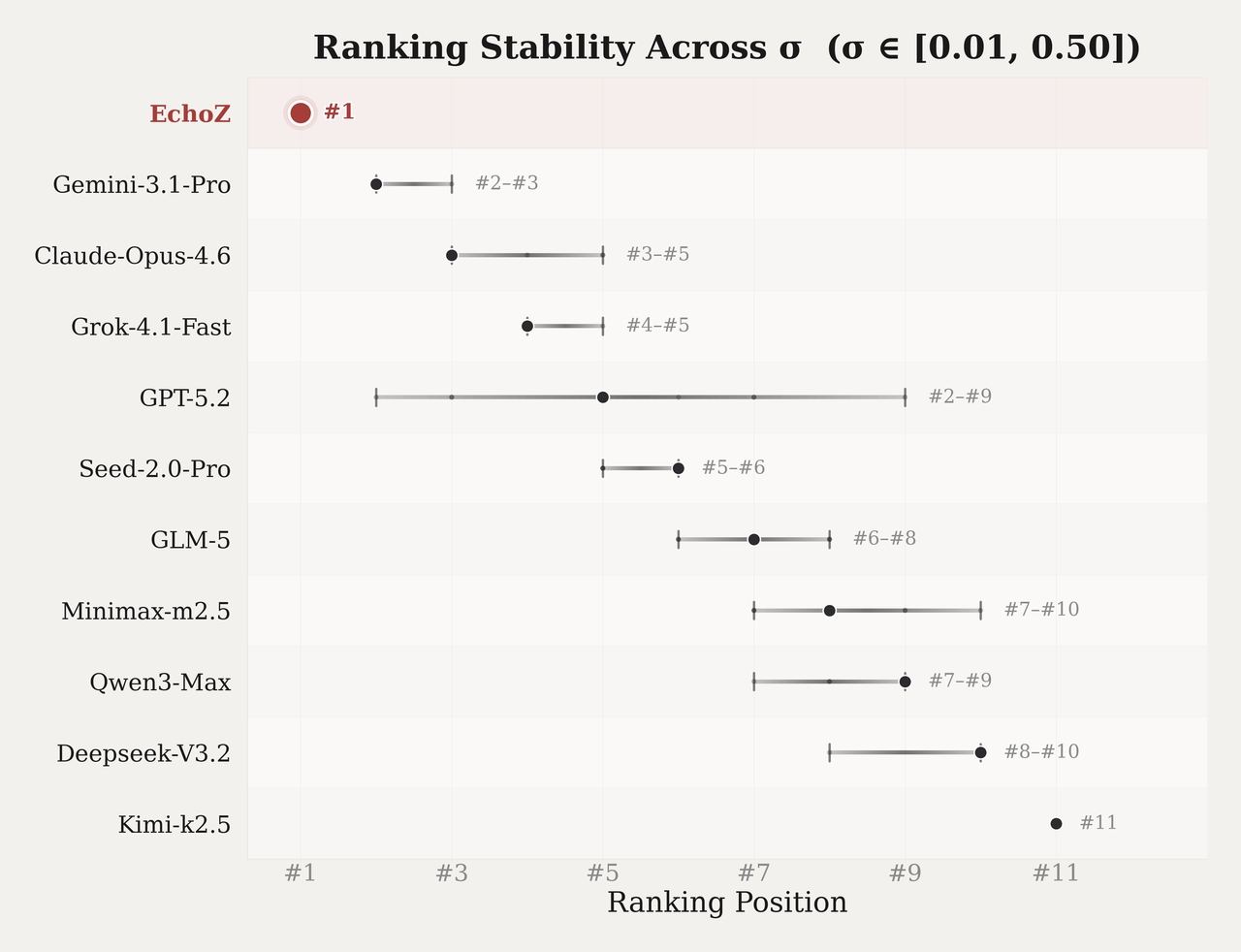
In the Elo framework, the parameter σ controls how Brier Score differences between two models are converted into win probabilities. When σ is small, a small Brier Score difference can produce a win probability close to 0 or 1, meaning that even a slightly better Brier Score on one question can strongly influence the battle outcome. When σ is large, the same difference produces a win probability closer to 0.5, and the ranking depends more on the number of battles won than on the size of each score gap.
The default value used in our framework is σ = 0.10. To check how much the ranking changes when σ varies, we sweep 9 values across σ ∈ [0.01, 0.50]. At each σ, we recompute the full Bradley–Terry ranking from all battles using the same data. For each model, we record its highest and lowest rank across the 9 evaluation settings.
Win Rate Against the Human Market
Each battle compares EchoZ with the human market on the same question within the same prediction batch. Win rate is then computed by Brier Score and stratified by domain (Politics & Governance), forecast horizon (7+ days ahead), and market certainty (human confidence 55%–70%).
AI-Native Prediction API
We are building an AI-native prediction API around EchoZ-1.0. Given a structured prediction question, the API is designed to return a fully grounded analytic report: a direct probabilistic answer, a stratified evidence base with source attribution, a counterfactual fragility assessment, monitoring recommendations, and a complete structured prediction record — each synthesised through a multi-round Map-Reduce agent cycle over live web evidence. The sample outputs below preview what a response looks like across the full domain taxonomy.
Sample API Output
Question: Which company will be the largest company in the world by market cap at market close ET on March 31, 2026?
Direct Answer: NVIDIA | Confidence: High
Probability Distribution
| Candidate | Probability |
|---|---|
| NVIDIA | 0.98 |
| Alphabet | 0.01 |
| Apple | 0.01 |
| Tesla / Amazon / Microsoft / Saudi Aramco | 0.00 |
Confidence Rationale
Driven by an insurmountable ~$700B mathematical buffer, combined with consistent market data showing low options volatility, resolved regulatory risks, and robust prediction market consensus (~98.7%).
Evidence Base
| Evidence | Why Decisive | Role |
|---|---|---|
| NVIDIA market cap ~$4.43T–$4.45T; ~$700B premium over Alphabet ($3.74T) and Apple ($3.71T) | A $700B gap is mathematically insurmountable in 9 trading days absent a historic catalyst | Direct |
| U.S. Commerce Dept. withdrew sweeping AI chip export rule on March 13, 2026 | Eliminates the most significant regulatory headwind before the target date | Supporting |
| Options market implies ±1.98% expected move heading into March 20 Triple Witching | Derivatives markets are not pricing in a gamma crash that could erase the 15%+ lead | Supporting |
| Qatar helium facility shutdown: supply chain risk, but TSMC has not halted production | Macro supply chain risk has not materialised into an acute factory shutdown | Supporting |
| Polymarket assigns ~98.7% probability to NVIDIA remaining #1 | Reflects overwhelming market consensus consistent with mathematical realities | Supporting |
Counterfactual Fragility: Low — A broad macro shock would impact the entire technology sector concurrently, preserving NVIDIA's relative lead. Only an idiosyncratic NVIDIA-specific Black Swan (e.g., C-suite fraud revelation, SEC trading halt) could reverse the prediction.
Monitoring Recommendations: Closing volumes and options volatility on March 20 Triple Witching · Qatar helium shortage escalation and TSMC production-halt risk · Unexpected idiosyncratic NVIDIA news · Unlikely megamerger announcements from Alphabet or Apple
Question: Who will win the 2026 Illinois Governor Republican primary election?
Direct Answer: Darren Bailey | Confidence: High
Probability Distribution
| Candidate | Probability |
|---|---|
| Darren Bailey | 0.9990 |
| Ted Dabrowski | 0.0004 |
| Rick Heidner / James Mendrick | 0.0001 each |
| Gregg Moore / Max Solomon / Joseph Severino / Other | 0.0001 each |
Confidence Rationale
Multiple authoritative media decision desks called the race; lead is mathematically certain (137K votes vs. ~34K remaining); legal challenges barred by the 95% vote-share threshold under Illinois election law.
Evidence Base
| Evidence | Why Decisive | Role |
|---|---|---|
| AP, NBC, CBS, NYT declared Bailey winner on the night of March 17, 2026 | Consensus among major national media decision desks is the primary indicator of a resolved result | Direct |
| Bailey holds 298,844 votes (53.5%) vs. Dabrowski's 161,087 (28.8%); lead of 137,757 vs. ~34,000 remaining | Margin is ~4× remaining uncounted ballots; reversal is mathematically impossible | Direct |
| Illinois law (10 ILCS 5/22-9.1) requires runner-up ≥ 95% of winner's total for discovery recount; Dabrowski at ~54% | Eliminates any legal pathway for challenging the result via recount | Supporting |
| Illinois Republican Party Chairman officially congratulated Bailey | Institutional recognition confirms Bailey as presumptive nominee | Supporting |
| Moore and Severino were removed from the ballot in January 2026; Solomon ran for State Treasurer | Confirms multiple listed options were not viable gubernatorial candidates | Supporting |
Counterfactual Fragility: Low — Only reversal scenario: sudden death or legal disqualification of Bailey prior to official certification (~April 7, 2026). Even then, Bailey would still have won the primary; Illinois Election Code Section 7-61 directs the Republican State Central Committee to fill the vacancy.
Monitoring Recommendations: Illinois State Board of Elections certification on/around April 7, 2026 · Breaking news regarding Bailey's health or legal eligibility prior to certification
Question: Will Ethereum (ETH/USDT on Binance) reach a new all-time high price by 11:59 PM ET on March 31, 2026?
Direct Answer: No | Confidence: High
Probability Distribution
| Outcome | Probability |
|---|---|
| No | 0.99 |
| Yes | 0.01 |
Confidence Rationale
Overwhelming mathematical improbability of a 112%+ gain in 13 days, combined with strong macroeconomic headwinds (Fed holding rates at 3.50%–3.75%, US-Iran conflict) and unanimous prediction market consensus.
Evidence Base
| Evidence | Why Decisive | Role |
|---|---|---|
| ETH/USDT ATH: $4,956.78 | Establishes the exact target price required for “Yes” resolution | Direct |
| Current price: ~$2,220–$2,340; requires ~112%–123% gain in 13 days | Establishes the baseline against which the target is assessed | Direct |
| USDT peg holds at $1.00; Binance order book deeply liquid ($35M at 2% depth) | Mathematically rules out artificial nominal price spike via Tether collapse or flash wick | Direct |
| Federal Reserve held rates steady at 3.50%–3.75% on March 18 amid US-Iran conflict | Confirms restrictive macroeconomic environment suppressing risk-asset parabolic rallies | Supporting |
| Polymarket assigns <1% probability to ATH by end of March | Demonstrates unanimous market consensus that the event is functionally impossible | Supporting |
Counterfactual Fragility: Low — The only viable reversal would be a catastrophic Tether peg collapse (>50% overnight), which would mathematically double the nominal ETH/USDT price. Given Tether's current profitability, regulatory cooperation, and strict auditing, this scenario is exceptionally unlikely.
Monitoring Recommendations: USDT peg stability for catastrophic deviations from $1.00 · Binance ETH/USDT order book and matching engine anomalies through March 31 · Emergency Federal Reserve weekend liquidity interventions
Question: Which team will finish as the #1 seed in the 2025–26 NBA Western Conference by the conclusion of the regular season on April 12, 2026?
Direct Answer: Oklahoma City Thunder | Confidence: High
Probability Distribution
| Team | Probability |
|---|---|
| Oklahoma City Thunder | 0.899 |
| San Antonio Spurs | 0.100 |
| Los Angeles Lakers | 0.001 |
| All others | 0.000 |
Confidence Rationale
Mathematical standings advantage (3.0-game lead with 13 games remaining), OKC primary stars healthy, magic number only 11, and SAS facing the league's toughest remaining schedule.
Evidence Base
| Evidence | Why Decisive | Role |
|---|---|---|
| OKC (54–15) leads SAS (51–18) by 3.0 games; both have 13 games remaining | Establishes OKC's commanding mathematical advantage | Direct |
| SAS holds head-to-head tiebreaker (season series 4–1 over OKC) | SAS needs only to tie OKC's final record — not pass them | Direct |
| SAS faces the #1 toughest remaining schedule in the NBA (.560 opponent win %) | Makes a flawless run required to close a 3-game deficit extremely difficult | Direct |
| OKC's magic number to clinch the #1 seed outright: 11 | OKC requires only moderate success to mathematically lock the seed | Direct |
| LA Lakers (43–25) have a max possible 57 wins; OKC currently has 54 | Confirms this is a two-team race | Supporting |
Counterfactual Fragility: Low — For SAS to steal the seed, a season-ending injury to Shai Gilgeous-Alexander or Chet Holmgren would need to trigger an OKC collapse while SAS runs the table against the league's hardest schedule.
Monitoring Recommendations: Outcome of NBA investigation into OKC resting 10 players (potential multi-game suspension) · Daily injury and rest status of Victor Wembanyama (ankle soreness) · San Antonio's performance during their early-April stretch against motivated playoff contenders
Question: Will another official trailer for Grand Theft Auto VI (GTA VI) be released by Rockstar Games or any of its official accounts by 11:59 PM ET on March 31, 2026?
Direct Answer: No | Confidence: High
Probability Distribution
| Outcome | Probability |
|---|---|
| No | 0.96 |
| Yes | 0.04 |
Confidence Rationale
Explicit corporate guidance directly contradicts a March timeline; absence of required technical and operational precursors; unanimous insider and market consensus against a March release.
Evidence Base
| Evidence | Why Decisive | Role |
|---|---|---|
| Take-Two CEO Strauss Zelnick explicitly stated GTA VI marketing begins Summer 2026 (Q3 2026 earnings call) | Explicit corporate guidance directly contradicts a March release timeline | Direct |
| As of March 18, Rockstar has not initiated its traditional 48–72 hour teaser protocol (logo changes, social media blackouts) | A digital teaser protocol is a historically required precursor to any major Rockstar trailer drop | Direct |
| ESRB rating remains “Rating Pending”; storefronts show only “Wishlist” functionality without active pre-orders | Backend prerequisites for a major trailer launch remain incomplete | Direct |
| Rockstar posted a three-week GTA Online roadmap concluding on April 1, 2026 | Creates a clean schedule gap only after the prediction window closes | Supporting |
| Tier-1 industry insiders (e.g., Tom Henderson) predict next GTA VI trailer in August 2026 | Credible leaks corroborate the corporate Summer 2026 marketing timeline | Supporting |
| Polymarket traders assess probability of a March 31 trailer release at 4% | Strong financial and crowd-sourced consensus against a March release | Supporting |
Counterfactual Fragility: Low — Reversal requires Take-Two to have deliberately misled investors during their Q3 earnings call and executed an unprecedented unannounced shadow-drop on March 31. If a sudden Rockstar social media blackout or unscheduled investor call materialised in the final week of March, “Yes” probability would rapidly exceed 80%.
Monitoring Recommendations: Rockstar official social media accounts for blackout protocols or logo changes in the final week of March · Internal YouTube API watchers or backend pre-order staging leaks · Unexpected SEC 8-K filings from Take-Two Interactive prior to March 31
Report Quality Assessment
The five case studies span the complete domain taxonomy — macroeconomic structure, electoral dynamics, digital asset markets, professional sports, and the entertainment industry — and collectively demonstrate that EchoZ-1.0 reports exhibit four defining qualities:
Conclusion
Echo constitutes a self-consistent prediction intelligence architecture in which the evaluation engine, training paradigm, and production API are mutually reinforcing rather than independently constructed. The multi-point aligned Elo framework resolves the timing-asymmetry and cold-start deficiencies that plague aggregated Brier Score approaches; the Train-on-Future pipeline breaks the engineering paradox of leak-free backtesting and substitutes outcome-oriented noise with behaviour-oriented signal; the Map-Reduce agent architecture translates the trained model's causal reasoning capacity into structured, evidence-grounded reports. EchoZ-1.0 consistently outperforms the human market across domains, forecast horizons, and market certainty levels, positioning it as a substantively capable forecasting agent across the full spectrum of domain-diverse prediction tasks.
Citation
If you find Echo useful in your research, please kindly cite:
@misc{unipat2026echo,
title = {Echo: Towards General AI Prediction},
author = {UniPat AI},
year = {2026},
url = {https://unipat.ai/blog/Echo}
}